

May 12, 2021 9 minutes read
Rating in the Openfabric ecosystem

The role of rating systems
Have you ever found yourself wondering just how many of the choices that we make when we’re navigating the Internet are influenced by other peoples’ opinions and experiences? Whenever we are deciding to watch a movie on a streaming platform or making a purchase, most of us will tend to briefly read the description of the one we are interested in. Then, however, a large portion of our time goes into trying to form an intuitive understanding of whether the object of interest is actually worth our commitment. This is accomplished mainly by taking time to weigh the ratings and reviews offered by the other people out there who have already interacted with the product and shared their views on it. And even though this process may be regarded as being significant only to the end-user, when it is replicated enough times, its results can ultimately serve to determine the product’s fate.
That is why, the focus of this article is to detail how the rating mechanism embedded into Openfabric works towards continuously refining the selection of algorithms that are available on the platform.
Making a difference
At its core, Openfabric is designed to create a new market for the smart AI solutions that are going to power the technology of tomorrow. Openfabric’s ethos is that shaping the future in a positive direction is something which can only be achieved by amplifying the voices of the community. And what better way to do so, than by allowing participants to easily express their opinions in a democratic fashion with the help of rating? In Openfabric, rating is accomplished by ensuring that any asset available on the platform (e. g. AI algorithms, datasets, computing infrastructure) is associated with an account which features the number of positive and negative reviews it has accumulated.
This mechanism directly involves the members of the Openfabric community in selecting the most capable and reliable of the platform’s assets. This involvement of the user at an individual level is bound to result in exponential benefits at the group level, and will also ensure that the Openfabric platform evolves into a steady and reliable source of high-end algorithmic artifacts that is going to bring wealth and renown to the community at large.
Additionally, decentralization of power manifests itself through the use of a rating system. As opposed to many of our platform’s direct competitors, Openfabric is designed to be as decentralized as possible, right from its initial phases. This stands in stark contrast to some alternative ecosystems which only offer access to curated AI solutions, while at the same time imposing high barriers to the adoption of innovative technologies. Our proposition, conversely, is that governance of the platform should be distributed among the peers in the community, and that from their interaction, a new type of swarm-like intelligence will emerge to drive the platform forward.
Technological implementation
Ensuring that each user who has interacted with an asset has the ability to rate their experience is a crucial element in Openfabric’s long-term development. As stated earlier, the AI algorithms and datasets will be associated with ratings of their performance, as experienced by the members of the ecosystem themselves. The ratings serve as a reference for the platform’s views about a given software or dataset. From a technological standpoint, the ratings are immutable and unforgeable, because they are persisted on a distributed ledger by leveraging the capabilities of smart contracts.
To expand upon the rating process, whenever a user decides to rate an algorithm or a dataset, they will call a smart contract by passing their numerical evaluation to that smart contract. In turn, the smart contract will then check the ledger in order to validate whether the user has had an interaction with the artifact in the recent past — and if that is the case, it will next append the rating to the list of available ratings for that particular asset, while concurrently marking the interaction as being evaluated, in order to avoid rating the same interaction multiple times. Having now described the technological building blocks of the rating mechanism, we will delve into the mathematical aggregation of the ratings later in this article. But before that, let’s take a moment to analyze the effects of the rating mechanism.
Impact at the assets level
The benefits of a rating mechanism on software and data assets are easily construed, when thinking about the mechanism in evolutionary terms. Within such a setting, the rating system plays the role of the selection mechanism, as well as the role of a proxy for the fitness function. The end-users of the algorithms play the role of the selection force, which is responsible for promoting revolutionary and innovative algorithms, while at the same time also discarding underperforming assets by decreasing their rating score.
The fitness of a specific algorithm or dataset is represented by the aggregation of all of the rating scores. The assumption that hides behind the selection force role of the rating system is that users who see an algorithm or dataset which has a low rating score are then going to avoid interacting with it — especially if they have to pay a fee for doing so.
Although biological evolution is a tediously slow process with no intrinsic end-goal, a digital counterpart that is set up with an end-goal in mind can prove to be a powerful tool. This is the ultimate role of the Openfabric rating system: to provide evolutionary pressure for the assets available on the platform in order to allow their rapid improvement within a compressed period of time. Such an evolutionary force will allow Openfabric’s users to witness the exponential growth of the platform’s value, which is completely directed by their ratings.
Impact at the service level
Rating mechanisms can be extrapolated from the assets layer, and can also be applied at the societal level. This is planned to be applied for algorithm, dataset and infrastructure providers alike. As opposed to being a force that discards underperforming algorithms, Openfabric regards applying the rating system at the societal level as being a method for promoting the members who extensively contribute to the platform, whether that be with intellectual property or with raw computing power.
To provide an example of the usage of the rating algorithm at this layer, let’s assume that a service consumer rents computing power for the execution of an algorithm from an infrastructure provider, but that the infrastructure provider fails to deliver the results in a specified timeframe. In this case, the service consumer is likely to add a negative rating for the provider, because they have failed to meet the contract requirements. In other cases, if the service consumer is pleased with the results of the AI algorithm and the dataset, then they can leave a favorable rating for the AI developer — as well as for the data scientist who compiled the dataset.
Mathematical considerations
From a mathematical perspective, the rating of an asset is made up of a two-dimensional array of positive and negative reviews. The question that arises is how the ratings — provided by the users — are aggregated into a single-value representation, while also churning out dishonest ratings and preventing the latter from influencing the overall rating of an asset.
Openfabric proposes a mathematical model which relies on Bayesian conditional probabilities to separate the honest reviews from the misleading ones. Furthermore, this model also favours recent reviews over those that have been received further back in the past, a feature which adds reliability and flexibility to the rating system. Openfabric’s mathematical model for rating is a beta probability density function defined by using a gamma function having two parameters — alpha and beta — which signify the number of positive and negative reviews, respectively, as in the following formula:
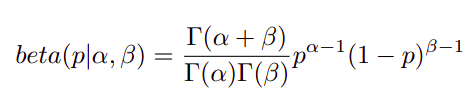
Using this function, one can obtain a rating for asset Z by performing a two-step process. Firstly, the aggregated score must be calculated using the following formula:
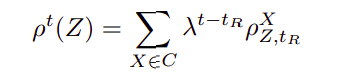
Where X are members of the community C, ρ is a vector of positive and negative review values cast by members X for asset Z at time TR t is the current time, and λ is an adjustable survival factor that favors more recent reviews. Next, the obtained value is plugged into the beta function presented above, and finally, the value is to then be inserted into the probability expectation function E, which has the following structure:
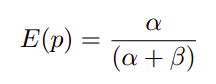
The result of this operation is the actual rating of an asset Z at time t, as described in the concluding formula of this article, where r and s represent positive and negative reviews:
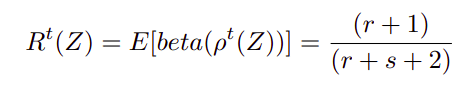
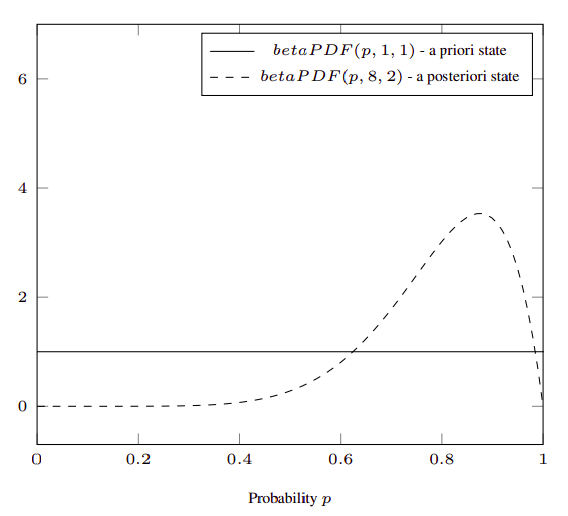
Underneath the mathematical complexity, one can clearly find the advantage that the rating system is robust, because it is not constrained by thresholds or constants. As mentioned earlier, this mathematical model will discard the exceptional or dishonest reviews, while at the same time adapting itself to the influx of ratings received from users, as depicted in the picture below, which describes the initial state for the reviews of an asset Z and the state of the probability density function after receiving seven positive ratings and one negative rating.
Conclusion
In this article, we have described some of the aspects concerning the general use of rating systems, as well as particularised their applications to the Openfabric ecosystem. We have presented the benefits of applying ratings to software assets, as well as the impact that doing so can have on the Openfabric service layer. And, last but not least, we have also revealed the mathematical model that enables the implementation of such a system. We have, however, left out the actual pseudocode that details how the mathematics are to be implemented, but you can find it in our whitepaper. As always, be sure to subscribe to our newsletter and follow us on social media. Together we can revolutionize the landscape of Artificial Intelligence systems in a new, unprecedented and exciting way!
